I think you were intentionally writing it in Simplified Chinese, but in hanja, it'd be 社會主義萬歲
AernaLingus
joined 3 years ago
Emiliano Zapata Salazar “It is better to die on your feet than to live on your knees.” - Novo General Megathread for the 7th and 10th of August 2025
Emiliano Zapata Salazar “It is better to die on your feet than to live on your knees.” - Novo General Megathread for the 7th and 10th of August 2025
PBS just released a documentary this past week called Atomic People about the survivors of the atomic bombs. I haven't watched it yet, but I have to imagine it's better than whatever the fuck James Cameron is cooking
edit: looks like it may originally be a BBC doco but the IMDB page is pretty sparse. I guess I'll find out when I watch it
Maxwell isn't allowed to play with the puppies at her new minimum prison camp in Texas due to the "sexual nature" of the crimes she was convicted of
The article doesn't imply that (emphasis mine):
The chief executive of Canine Companions, the group that runs the puppy program at the prison in Texas, told NBC News that Maxwell is not allowed to interact or play with the puppies due to her the nature of her crimes.
“We do not allow anyone whose crime involves abuse towards minors or animals — including any crime of a sexual nature,” Paige Mazzoni, the head of Canine Companions, told NBC News.
“That’s a hard policy we have, so she will not be able to," she added.
Mazzoni explained that these policies are in place to protect the puppies.
“Those are crimes against the vulnerable, and you’re putting them with a puppy who is vulnerable,” she said.
It seems they're operating under the assumption that a history of child abuse is correlated with (or predisposes you to) animal abuse. Whether that's true, I can't say. Doesn't seem absurd, but that doesn't make it true.
Emiliano Zapata Salazar “It is better to die on your feet than to live on your knees.” - Novo General Megathread for the 7th and 10th of August 2025
I want to be able to read my news in my rss reader, without having to have an entire web browser in it too.
Agreed! Although, with the example above, which only contains the short descriptions, my RSS reader (ReadYou for Android) is able to quickly fetch the full blog post without any extraneous material (headers, footers, sidebar, etc.) if I have the "Parse full content" setting enabled for that particular feed. Honestly not super sure how it works—maybe the post itself has some hints in the markup, or the reader has a heuristic that happens to work in this case but fails in others. If it's something that can be set up to work without fail, though, the advantage is that the RSS feed itself is more lightweight by a few orders of magnitude.
...nvm, I checked the source code and it's definitely a heuristic, so it could fail in some cases, making heavy feeds a safer bet. I guess that's something that can be addressed with pagination, anyhow, although I can't speak to how well that's supported by feed generators or readers.
Emiliano Zapata Salazar “It is better to die on your feet than to live on your knees.” - Novo General Megathread for the 7th and 10th of August 2025
I think I have a more concrete answer for you! If you hit the /site API endpoint^[You actually don't need to mess around with the API if you don't want to: if you just go to the Hexbear homepage, the entire JSON object is visible directly in the HTML source. Specifically, you'll find it at the top of the <head> contents inside <script nonce="undefined">; you can also simply type window.isoData into the console and hit Enter, since that script tag is simply assigning the object to that variable.], you get a big ol' response with all kinds of info, but the relevant path is .site_res.site_view.local_site_rate_limit, which contains this value:
{
"local_site_id": 1,
"message": 180,
"message_per_second": 60,
"post": 6,
"post_per_second": 600,
"register": 4,
"register_per_second": 3600,
"image": 6,
"image_per_second": 3600,
"comment": 12,
"comment_per_second": 300,
"search": 60,
"search_per_second": 600,
"published": "2023-06-17T20:29:44.499734Z",
"import_user_settings": 1,
"import_user_settings_per_second": 86400
}
This might be a little opaque, especially since the [action_type]_per_second key names are misleading, but the rate limiter bucket update() function in the backend has a helpful explanatory comment:
For
secs_since_last_checkedseconds, the amount of tokens increases bycapacityeverysecs_to_refillseconds. The amount of tokens added per second iscapacity / secs_to_refill. The expression below is like
secs_since_last_checked * (capacity / secs_to_refill)but with precision and non-overflowing multiplication.
So in the case of our image rate limit, it means that the bucket has a maximum capacity of 6 tokens and refills at a rate of
3600 sec / 6 tokens = 600 sec / token = 10 min / token
Unfortunately, as I said before, there doesn't seem to be a way to proactively query how many tokens you have remaining for any given action (although it seems like they're working on it!). However, with the above knowledge you can monitor it yourself, which could be useful if you're writing a script. Even in the manual case, the moment you hit a rate limit you can set a timer to know when you'll be able to complete your indicated action.
For instance, let's say you're uploading images and you hit the rate limit error, but you still have 4 images to upload. You can set a timer for 10 min * 4 = 40 min and be confident that you'll be able to upload the remaining images after that waiting period^[The timer should technically be counting from the moment you upload your first image (assuming less than 10 minutes pass between when you upload the first image and the sixth) but the method I describe is assuming you're not paying close attention and giving you a simple upper bound].
If you have more actions to take than the maximum capacity, then you'd set your timer for the time listed by the API (i.e. the time for a bucket to refill from empty, complete the full amount of actions permitted, and then set your timer for the remainder. For instance, if you wanted to upload 9 more images after hitting the rate limit, you would set your timer for the refill time listed (3600 sec = 1 hour), upload 6 images, then set your time for 10 min * 3 = 30 min to know when to upload the remaining 3.
TL;DR: You can upload a maximum of six images in quick succession (i.e. in less than ten minutes), and the tokens for image upload regenerate at a rate of one token every ten minutes.
Emiliano Zapata Salazar “It is better to die on your feet than to live on your knees.” - Novo General Megathread for the 7th and 10th of August 2025
Emiliano Zapata Salazar “It is better to die on your feet than to live on your knees.” - Novo General Megathread for the 7th and 10th of August 2025
An RSS feed is basically just a way for someone to provide structured data about some resource (podcast episodes, web comics, articles, torrents...could be anything), typically in reverse chronological order. Each entry in the feed contains metadata such as the title, date posted, header image, description, tags, duration, and article snippet; it also typically includes a link to the actual resource (article, MP3 file, torrent file, etc.), although with text-based resources you'll sometimes see the whole damn thing in the feed.
The idea is that you can stick a bunch of these feeds into some kind of software which will then reload the feeds on a regular basis to see if any new entries have been added. You can stick a podcast RSS feed in your podcast app and have it automatically download new episodes when they're posted; you can stick a bunch of blog RSS feeds into an RSS reader to keep track of your favorite writers; you can stick a torrent RSS feed in your torrent client and configure it to automatically download new torrents.
Also, since I realized I haven't been explicit: an RSS feed is literally just a text file formatted in a specific way so that a computer can parse it. But you don't have to be a computer to parse it—you can look at it and understand it as a human, too. Here's a short example of an RSS feed from a blog which you should be able to view in your browser:
If you use a podcast app, it's probably using RSS under the hood without you even knowing. But I think the article/comic example is more interesting, since it's a way to take control back from algorithmically-dictated feeds. Instead of just scrolling in the hopes that something you like will appear amongst the slop, you can curate a selection of people whose work you like and keep up with them without having to check 30 different websites every day. It's especially great for following creators who post infrequently, since they can easily get lost in the firehose of information that is the feeds of the major platforms.
edit: minor spelling mistake
I thought it was gonna be a different kind of train song, but this is neat, too!
Can't go wrong with Chattanooga Choo Choo or Take the "A" Train
 The important thing is that you know now, and it's not like you do much besides administrative stuff and a course overview in the first week, anyhow. Good luck with your classes—you got this!
The important thing is that you know now, and it's not like you do much besides administrative stuff and a course overview in the first week, anyhow. Good luck with your classes—you got this! 
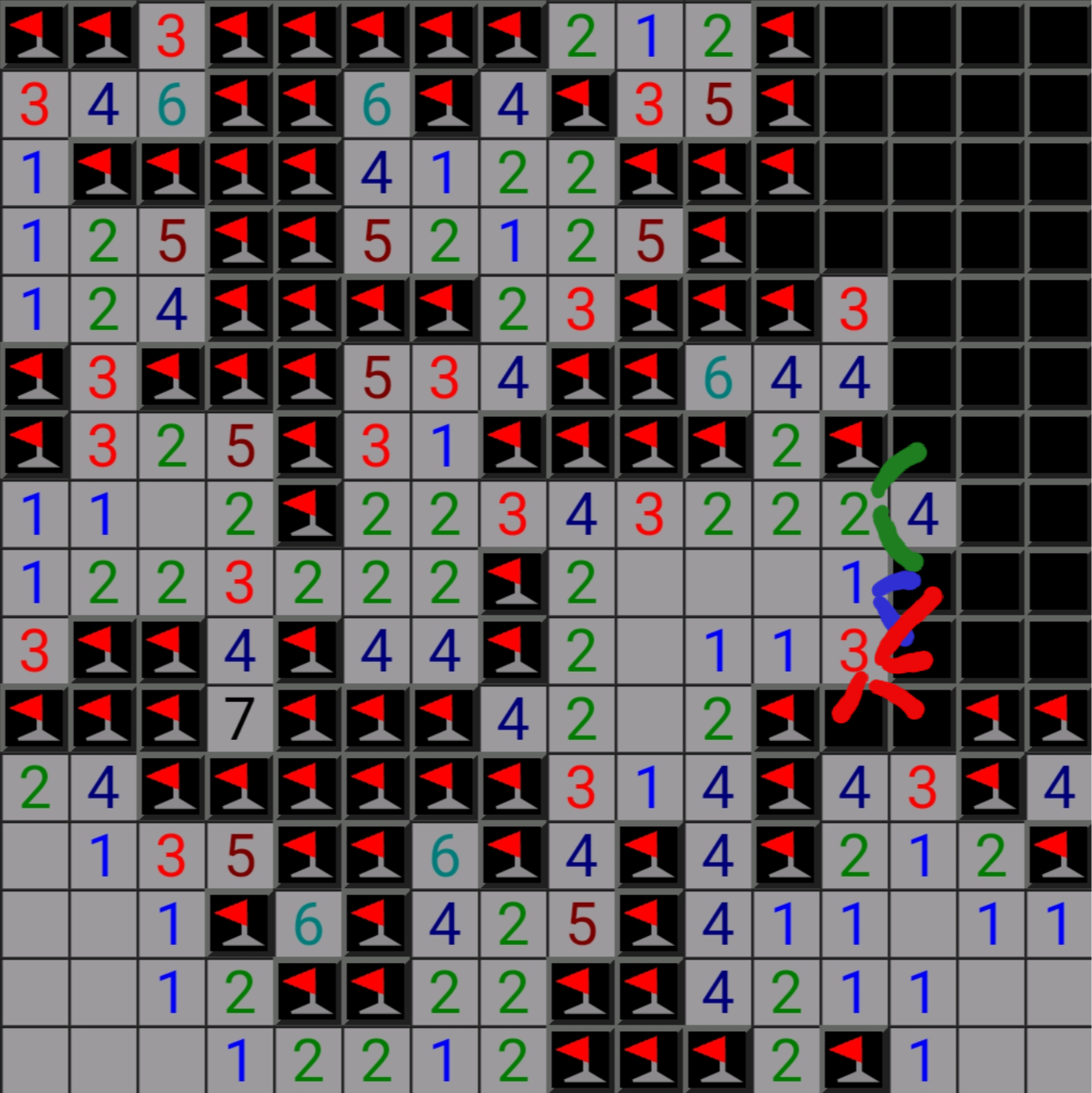
Ever since I got introduced to the joys of Minesweeper by Girl_DM_ I've been having a lot of fun playing it as a little timewaster. I'm specifically playing the version from Simon Tatham's lovely Portable Puzzle Collection (more specifically the Android port via F-Droid) which unlike the original Minesweeper does NOT require guessing. Most of the time, I'm well-versed enough in patterns and testing candidate solutions that I'm able to clear a 16x16 board with 99 mines in about 3-5 minutes. But on a fairly regular basis I'll run into situations where I get stuck and it seems like I'd either have to calculate an inordinate amount of possible solutions or just make a random guess, neither of which are appealing. Here's one such example:
with annotations
without annotations

There's probably some cool Minesweeper shorthand I could use to describe the constraints, but what I tried to show with my annotations is how I understand that, for each of the annotated squares, there is a mutually-exclusive binary choice (or in the case of the 3, two choices) for where a mine could be located. Unfortunately, as far as I can tell, while the choices are internally mutually exclusive, it doesn't seem like there's any permutation of those choices that is invalid so I can't eliminate any possibilities. My usual strategy is to fix one choice and see if it results in a contradiction. For instance, if the other mine for the 2 is the upper choice, we can clear the lower square. That means the lower square for the 1 must be a mine, and this still leaves either of the two bottom choices as valid for the 3 (so this is a possible configuration based on these constraints).
The only remaining sections have a lot of freedom which makes them daunting to analyze. Of the remaining unanalyzed squares, from top to bottom they have 2, 2, and 3 mines remaining, respectively, which is quite a lot of options to fully check, and I can only eliminate a few heuristically (e.g. the top 3 must have at least one mine in either the east or southeast space, since otherwise the 4 to the south can't be fulfilled; the 4 must not have the remaining mines all in the east column because otherwise the 2 and 1 can't be fulfilled). I'm sure if I went through them methodically I would eventually arrive at an answer, but that's pretty tedious, so I usually just give up and generate a new board in this kind of situation.
TL;DR: am I missing some neat heuristic(s) that will allow me to either slash the possible solutions to a more manageable number or eliminate individual solutions very quickly, or is this kind of difficult spot just an inevitable outcome for some boards?
Even today, probably the best vibes I have surfing the web is when browsing fansites. Blue Moon Falls had me fooled as being from the old days, but it's actually made by a youngin who really captures that old fansite feel. She semi-recently made this really neat tool that tries to replicate the experience of using one of the Pokémon event distribution stations they had at the NYC Pokémon Center back in the early 2000s. Another great Pokémon fansite that really is from the old days is The Cave of the Dragonflies which has all sorts of neat info about Pokémon (if you've ever thought that the capture mechanics in the Gen I Pokémon games were bullshit, do I have a post for you!).
What I love about both of those sites is their eclectic nature which so exemplifies what the early net was like; Cave of the Dragonflies in particular has all kinds of stuff—movie reviews, fanfiction, crossword puzzles, link hunts, you name it! Rather than a trough of "content" aimed at maximizing ad revenue or "engagement", they're an expression of what each webmaster thinks is neat and wants to share with the world. That's the passion that made the early web great, and it's worth breaking out of our filter bubbles to seek it out.