cross-posted from: https://lemmy.ml/post/4027414
TIL that I can use Perl's
Benchmarkmodule to time and compare the performance of different commands in an OS-agnostic way, ie as long as Perl is installed.For example, to benchmark curl, wget and httpie you could simply run:
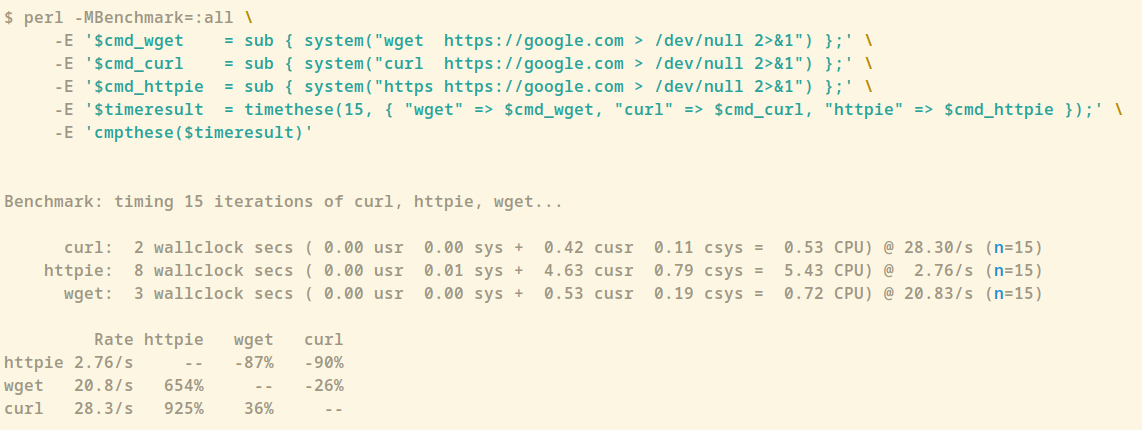
$ perl -MBenchmark=:all \ -E '$cmd_wget = sub { system("wget https://google.com > /dev/null 2>&1") };' \ -E '$cmd_curl = sub { system("curl https://google.com > /dev/null 2>&1") };' \ -E '$cmd_httpie = sub { system("https https://google.com > /dev/null 2>&1") };' \ -E '$timeresult = timethese(15, { "wget" => $cmd_wget, "curl" => $cmd_curl, "httpie" => $cmd_httpie });' \ -E 'cmpthese($timeresult)'which on my old T530 produces:
Benchmark: timing 15 iterations of curl, httpie, wget... curl: 2 wallclock secs ( 0.00 usr 0.00 sys + 0.42 cusr 0.11 csys = 0.53 CPU) @ 28.30/s (n=15) httpie: 8 wallclock secs ( 0.00 usr 0.01 sys + 4.63 cusr 0.79 csys = 5.43 CPU) @ 2.76/s (n=15) wget: 3 wallclock secs ( 0.00 usr 0.00 sys + 0.53 cusr 0.19 csys = 0.72 CPU) @ 20.83/s (n=15) Rate httpie wget curl httpie 2.76/s -- -87% -90% wget 20.8/s 654% -- -26% curl 28.3/s 925% 36% --Very handy indeed ❤