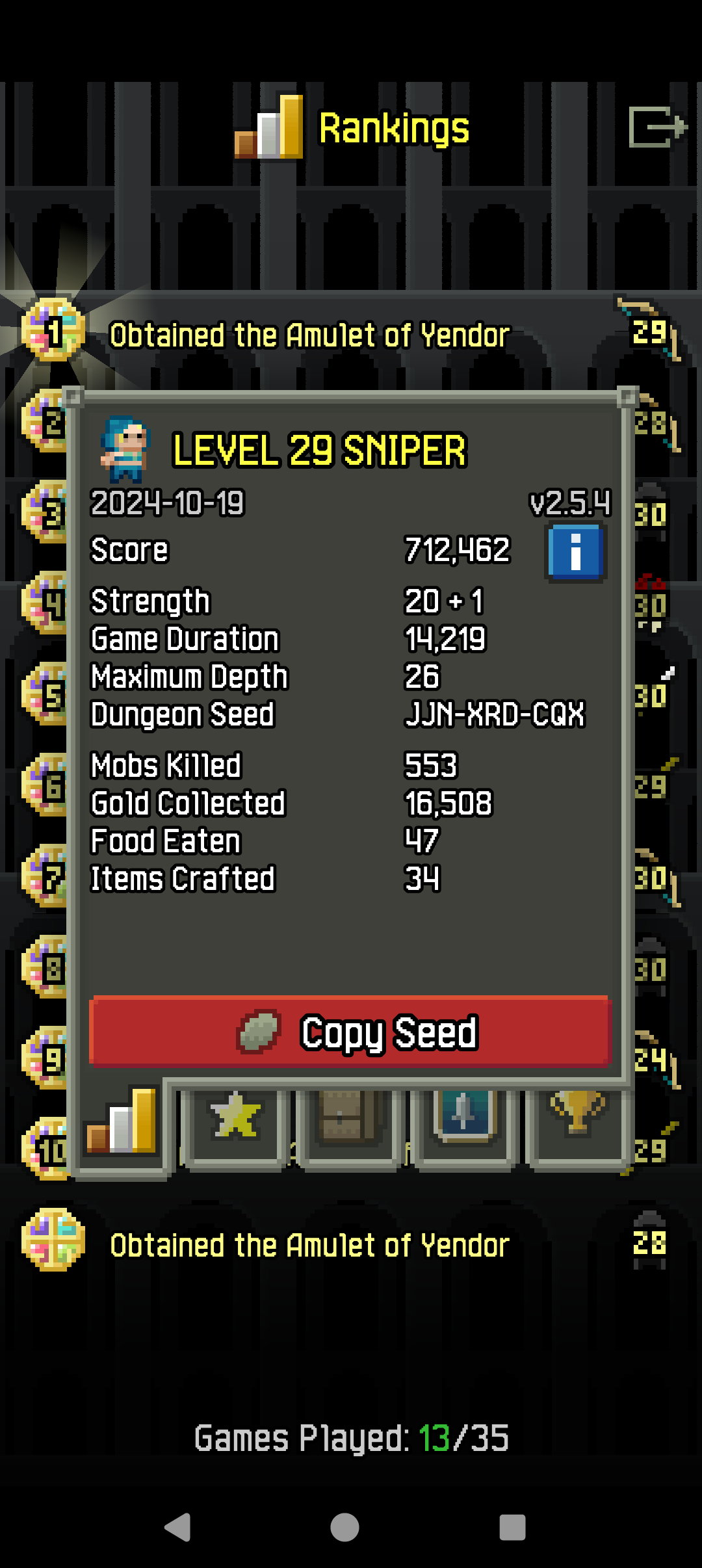
It turned out not much harder than 3 challenges:
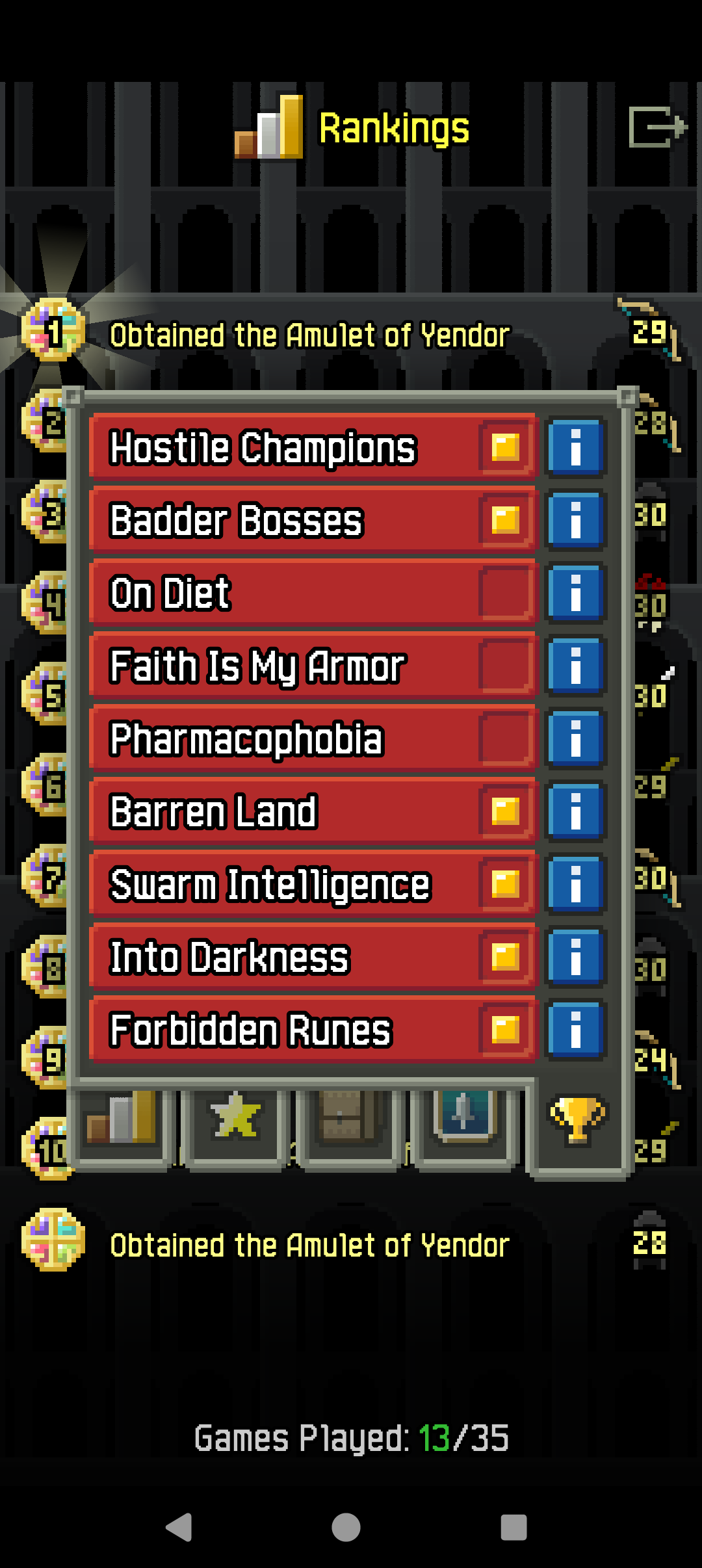
- Hostile Champions doesn't even annoy too much.
- Badder Bosses is an easy one.
- Barren Land is very manageable. You can't bless Ankhs, but you don't have to rely on them if you don't make major mistakes.
- Was worried a bit about Swarm Intelligence, but it wasn't too bad.
- Into Darkness was basically negated by the Eye of Newt. And then I got lucky with a projecting bow.
- Chose huntress because of Forbidden Runes.
The armour ability is most useful for running for cover from disintegration beams.
Saved 5 health potions for depth 25 (Evil Eyes were a massive headache), spent them all and eventually had to resort to a scroll of retribution to finish Yog-Dzewa (was partially surrounded with <10hp and had no means to avoid the gaze attack, it had 33hp thanks to a well-timed bee). Alchemy and a projecting bow combined made the fists much easier to deal with, but I didn't have enough breathing windows to use more than 50% of the potions I had.
Then I decided against ascending (and I don't like spending the time on that when the run is purely for an achievement and doesn't require it).
The only badge with non-trivial requirements remaining is the 1000000 score one, which would be easier with an additional challenge added (I don't feel confident enough to do another Doom Slayer with so many challenges). Which should I do?
- On Diet: not sure if I'd make it, I had to use potions of cleansing for food 2-3 times even without the challenge this run (+a few more times on depth 25).
- Faith Is My Armor: don't know how I'd handle the effective lack of armour with Swarm Intelligence on. On the other hand, nothing needs SoUs and they could be invested in rings...
- Pharmacophobia: no.

Thanks! I now see that Tai Chi is mentioned frequently online in context of the film unlike yoga so that should be right; it narrows things down.